Airflow Deployment¶
This page outlines the deployment of Airflow infrastructure and services.
Docker Image¶
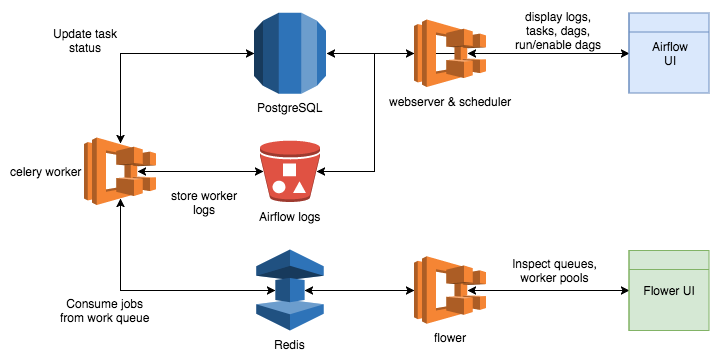
A single docker image with Airflow and other dependencies, such as gunicorn, flower, and celery, is built from the Dockerfile in the root of the directory. What service is actually run is determined from the command passed to the container.
webserver will run the Airflow UI
scheduler will run the task scheduler
worker will run a celery worker
flower will run the flower UI for monitoring celery
Persistance¶
There are three methods of persistance used by Airflow and its services:
Postgres via RDS¶
Postgres stores history about dags, tasks, task runs, and so on. The Airflow datamodel is well documented here.
Redis via Elasticache¶
Redis is used as a broker for a Celery task queue. When the web ui or scheduler needs to run a job, it places the job on the Redis queue for future consumption by Celery executors running in the worker containers.
S3¶
S3 is used to store task logs. Because tasks are run on worker containers that may be added or removed at any time, the logs need a persistant place to be stored. After a task runs, its logs will be uploaded to S3 where the Airflow webserver will be able to retrieve and display them in the UI for debugging.
Deployment¶
ECS Tasks¶
There are three ECS Tasks defined for the Airflow deployment.
airflow with the webserver and scheduler container running
worker with celery executor container running
flower with the flower ui container running
Having each of these three seperate definitions allows us to scale each independently as they are under their own Target Group.
Eg: the workers will need to scale up when many tasks are being run, but the web server will not.
CI/CD¶
The CI/CD strategy follows the Kids First process and is the same as any other code repository. Care needs to be taken as the webserver and workers may have brief periods where they are out of sync during a deployment and so the code executed on a worker may not be what’s displayed in the UI.